“If I could, I would make tomorrow’s Open Science infrastructures available today” – Dr. Peter Kostädt, Chief Information Officer (CIO) of the University of Potsdam
Open Science stands for science that is open, transparent, and as freely accessible as possible: What does your personal Open Science utopia look …
The Collaborative Indo-German Project Co-PREPARE – Dr. Jürgen Mey, University of Potsdam & Prof. Ankit Agarwal, Indian Institute of Technology, Roorkee
Co-PREPARE – What is it about?
Dr. Jürgen Mey: The project deals with natural hazards in the Himalayas. The challenges of global change come together …
From the Lab to Industry – A visit to the innoFSPEC Transfer Lab
The Innovation Center innoFSPEC (innovative faseroptische Spektroskopie und Sensorik) was created as a joint venture of the University of Potsdam and …
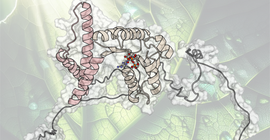
“Our Goal is to Develop an Alternative to Antibiotics” – Matthias Hartlieb and his team research synthetic polymers for biomedical applications
Dr. Matthias Hartlieb has declared war on antibiotic-resistant germs and, together with his colleagues, is researching how the properties of polymers …
Enormous gains – Eight years ago, Miriam Vock initiated Germany’s first qualification program for refugee teachers
How would I feel if I had to flee with my child from war and persecution to a foreign country, a country whose culture I don't know and whose language …
Hydrologic models and climate change – Humboldt Fellow Patricio Yeste guest at the University of Potsdam
The research of Dr. Patricio Yeste involves the application of hydrologic models and the analysis of climate change impacts on water resources. Since …

 und Prof. Ankit Agarwal (m.) zusammen mit Dr. Wolfgang Schwanghart.")






 with intake tower.")