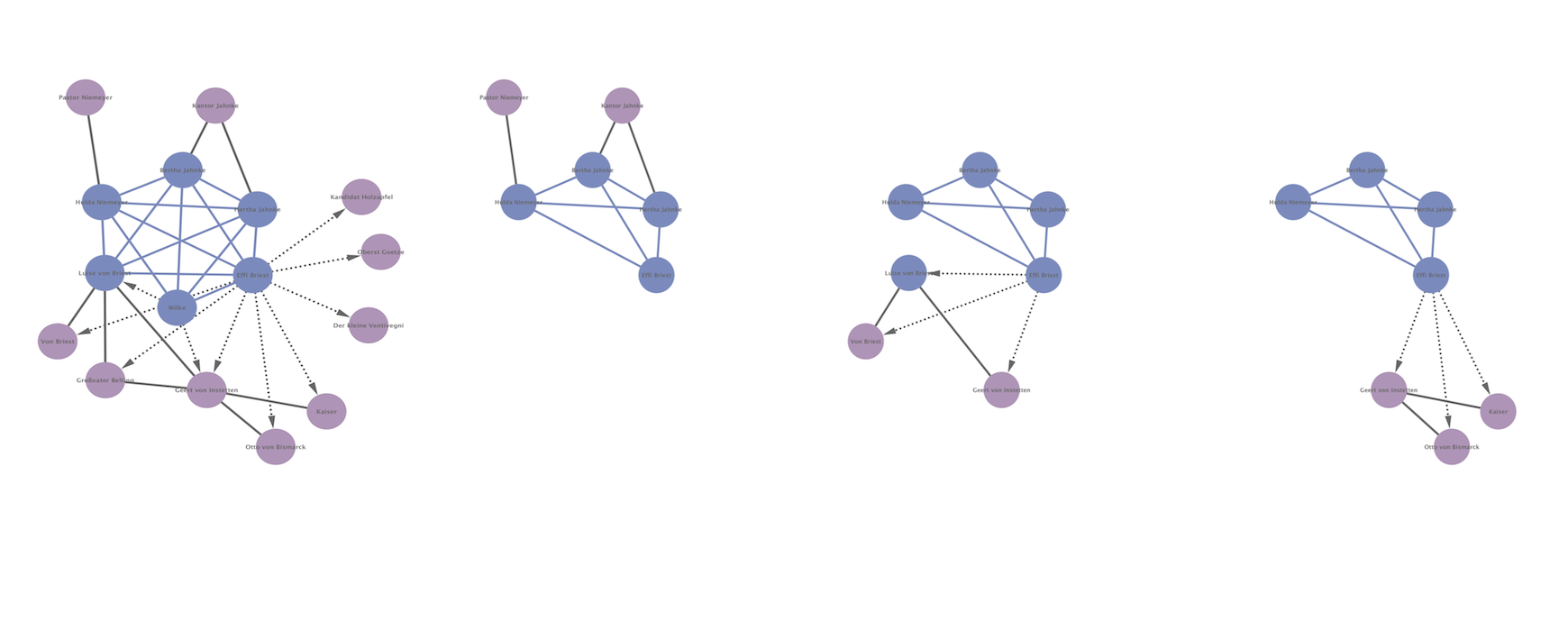
Graphen einer Netzwerkanalyse von Fontanes »Effi Briest«, work in progress, siehe auch diesen Video-Tweet
Zukünftig wird über die Aktivitäten zu diesem Projekt auf der Website des Theodor-Fontane-Archivs unter der Rubrik »Distant Reading Fontane« informiert.
Distant Reading Fontane
[Version 15.6.2016]
Welche Wörter, Wortfolgen oder Wortarten kommen überdurchschnittlich häufig in den Werken Theodor Fontanes vor? Wie unterscheiden sich die einzelnen Romane hinsichtlich ihrer Worthäufigkeiten oder hinsichtlich ihrer Satzlängen, wie unterscheiden sich die fiktionalen Texte von den faktualen, etwa den Wanderungen? Auf welche Weise baut Fontane seine Figurenensembles auf, wie sind, anders gefragt, die Figurennetzwerke der Romane beschaffen? Und wie entwickeln sie sich jeweils im Verlauf der Handlung? –
Und, nicht zuletzt, was vermögen uns die Antworten auf diese und vergleichbare Fragen über das poetische Schaffen Fontanes zu sagen?
Unter dem Titel ›Distant Reading Fontane‹ sollen in Zukunft Aktivitäten und Vorhaben zusammengefasst werden, die sich die explorative, teils experimentelle Anwendung von computergestützten Analysemethoden insbesondere auf das Erzählwerk von Theodor Fontane zum Ziel gesetzt haben. Das Projekt ist ergebnisoffen, es soll zugleich darum gehen, die Methoden und deren Ergebnisse kritisch zu diskutieren und zu evaluieren.
Ergebnisse des Projekts sollen aus dem work in progress heraus publik gemacht werden. Zwei Teilprojekte, die sich gerade in der Konzeption befinden, werden weiter unten auf dieser Seite in Form von Teasern präsentiert:
- erstens ein Teilprojekt, in dem Fontanes Romanwerk netzwerkanalytisch aufbereitet und zum einen statistisch analysiert, zum anderen dynamisch visualisiert wird (»Fontanes Romannetzwerke. Dynamische Graphen«);
- zweitens ein Teilprojekt, das Ergebnisse der Stilometrie, des Topic Modeling etc. als kuratierte Daten-Edition präsentiert (»Distant Reading Fontane. Poster Edition«)
Alle Ergebnisse sowie deren (Re-)Präsentationen befinden sich noch im Entwicklungsstadium.
Distant Reading
›Distant Reading‹ (die Bezeichnung stammt vom Stanforder Literaturwissenschaftler Franco Moretti) ist als Methodenbegriff ebenso schillernd wie unscharf (siehe dazu auch den Artikel von Frank Fischer und Peer Trilcke für den foucaultblog), meint aber zumeist eine literaturanalytische Herangehensweise, bei der, häufig mittels digitaler Verfahren, nicht mehr Einzeltexte untersucht werden, sondern größere Textmengen – Textmengen, die sich gar nicht oder nur mit sehr großem Aufwand mittels eines close reading (›nahen Lesens‹) erschließen lassen.
Aus meiner Sicht lässt sich die Herausforderung, die der ›Distant Reading‹-Begriff für die Praxis, Methodik, Terminologie und Theorie der Literaturwissenschaften darstellt, auf die einfache Frage bringen: »Wie lese ich Texte aus einer anderen Distanz als der Nähe?«. Dieser Frage gilt es, unter den Bedingungen der Digitalisierung, nachzugehen.
Ziel dieses Teilprojektes ist es, Figurennetzwerke aus Fontanes Erzählwerken zu extrahieren, zu analysieren und zu visualisieren. Dabei soll eine narratologisch reflektierte Beschreibung von Netzwerkstrukturen erfolgen, wie sie sich bisher nicht mit voll-automatisierten Verfahren durchführen lässt. Insofern findet im Rahmen des Teilprojektes auch eine grundsätzliche Reflexion über die Modellierung und die dynamische Visualisierung von Romannetzwerken statt. Vor allem aber sollen die Ergebnisse der Analysen neue Einsichten in die Plotstrukturen der Erzählwerke von Fontane ermöglichen.
Das Projekt befindet sich noch in der Konzeptualisierungsphase, derzeit werden erste Datenerhebungsroutinen und Datenmodellierungsoptionen an ausgewählten Textausschnitten erprobt. Während dieser Testläufe ist ein früher Prototyp einer Visualisierung des ersten Kapitels von Effi Briest entstanden.
»Effi Briest«, Kapitel 1 – als dynamisches Netzwerk [Prototyp]
»Effi Briest« Ein dynamisches Netzwerk [Alpha-Version, segmentiert nach Kapiteln]
Ende Juni 2016 entstand nach einer händischen Erhebung von ca. 15.000 netzwerkanalytisch relevanten Datenpunkten zu »Effi Briest« diese, wohl weniger als 2 Prozent der erhobenen Daten ausnutzende Visualisierung:
So problematisch Morettis ›Distant Reading‹-Techniken aus Sicht zumal der streng empirischen Forschung sein mögen, so inspirierend ist zugleich seine kreative Befragung der Daten hin auf einen Sinn, der sich auch innerhalb der Literaturwissenschaft kommunizieren lässt.
Anders gesagt: Man kann Moretti durchaus vorwerfen – und einige Kritiker haben das auch getan –, dass er die quantitativen Daten mit qualitativen Techniken interpretiert, also im Grunde die Daten einem (unangemessenen) close reading unterzieht. Man kann diesen Versuch aber auch interessant finden. Nur muss man sich in diesem Fall gleichzeitig die Frage stellen, in welcher Form diese Daten vorliegen.
Liegen diese Daten etwa als Zahlen vor, als statistische Werte, dann steht die qualitative Interpretation in der Tat vor erheblichen Herausforderungen. Ob diese unlösbar sind (was ich nicht glaube), muss an einem anderen Ort diskutiert werden. Wichtiger ist an dieser Stelle, dass der Output der quantitativen Analyseverfahren keineswegs aus Zahlen bestehen muss. Er kann z.B. auch in Form von Visualisierungen vorliegen (siehe die Materialien zu ›Fontanes Romannetzwerken‹ oben); oder aber in Form von sortierten, extrahierten, permutierten etc. Wortlisten.
In diesem Teilprojekt sollen solche Wortlisten erstellt werden. Diese geordneten Wortlisten lassen sich dabei durchaus ›nahlesen‹, nur stehen die jeweils gelisteten Wörter, Wortfolgen oder Textpassagen nicht mehr in ihrem ursprünglichen syntagmatischen Zusammenhang, sondern wurden nach diversen Paradigmen neu arrangiert.
Ziel des Projektes ist es, diese neu arrangierten Materialien kuratiert, und in mehreren Serien, als »Distant Reading Fontane. Poster Edition« zu publizieren.