PhD-Project P1 by Ugur Öztürk (UP):
Landslide prediction under changing boundary conditions
Timescale: Oct. 2015 – Sept. 2018
Supervisors:
Prof. Dr. Oliver Korup, University of Potsdam
Prof. Dr. Jürgen Kurths, Potsdam Institute for Climate Impact Research (PIK)
Background
Quantitative studies that aim at predicting where and when landslides occur in a given area of interest have taken centre stage in the research literature on mass movements. Over the last two decades, researchers have adopted multivariate statistical tools from the fields of data mining and machine learning to predict the spatial and temporal susceptibility to landslides from detailed inventories. These data sets are matrices containing n observed landslides with m characteristics each, including e. g., geographic position, landslide size, topography, rock type, soil and groundwater conditions, distance from fault lines, river or road networks. Some of the more widely used methods such as multivariate logistic regression, artificial neural networks, or Bayesian Weights-of-Evidence have routinely produced prediction success rates of >80% (Korup & Stolle, 2014). This optimistic prospect in spatial landslide prediction is at odds with recent re-assessments of global landslide damage: Nearly 32,000 people have died because of landslides between 2004 and 2010 alone, shadowing previous estimates, and inviting more reliable methods of landslide early warning.
Some of the key problems that limit the predictive capacity of these models include overfitting, poorly constrained data quality, and missing data. Further uncertainty comes from insufficiently time-stamped landslide data, let alone the many transient causes and triggers that compromise prediction of landslides in times of climate and global change. Hence, landslide prediction mainly deals with mapping susceptibility under static scenarios. Dynamic prediction of the timing of landslides, on the other hand, and whether they are clustered in time has remained challenging (Korup et al., 2012).
Objectives and Methods
The PhD-project dealt with precipitation and earthquakes as triggers of landslides.
Main results:
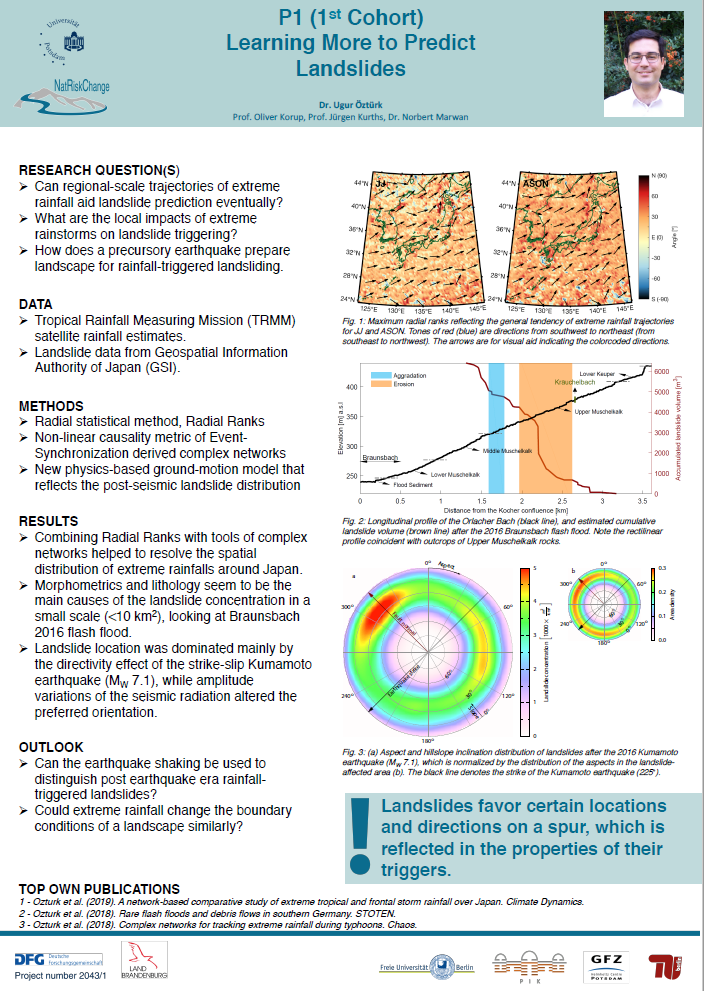
- A radial statistical method was developed, namely Radial Ranks. Combining Radial Ranks with tools of complex networks helped to resolve the spatial distribution of extreme rainfalls tied to tropical cyclones in and around Japan much better than eye-of-the-storm trajectories. Such practices could aid overall understanding of landslide distribution in country scale applications.
- Looking at the extreme rainfall induced landslides in a small scale (<10 km²), morphometrics and lithology seem to be the main causes of the landslide concentration in Orlacher Bach, Germany, triggered by extreme rainfall in 2016. Thus the morphometrics and lithology play a key role on distribution of landslides in catchment scales.
- Topographic variations alone cannot explain the distribution and orientation of landslides triggered by the Kumamoto 2016 earthquake (MW 7.1), Japan. Instead, landslide location was dominated mainly by the directivity effect of the strike-slip earthquake, while amplitude variations of the seismic radiation altered the preferred orientation.
Publications within NatRiskChange:
AGARWAL, A., BOESSENKOOL, B., FISCHER, M., Hahn, I., Köhn, L., LAUDAN, L., MORAN, T., OZTURK, U., Riemer, A., Rözer, V., SIEG, T., VOGEL, K., WENDI, D., Bronstert, A., Thieken, A.H. (2016): Die Sturzflut in Braunsbach, Mai 2016 - Eine Bestandsaufnahme und Ereignisbeschreibung. Taskforce im Rahmen des DFG-Graduiertenkollegs Natural Hazards and Risks in a Changing World, Universität Potsdam (Publisher), 20 pages, urn:nbn:de:kobv:517-opus4-394881.
AGARWAL, A., Marwan, N., OZTURK, U., Rathinasamy, M. (2019): Unfolding Community Structure in Rainfall Network of Germany Using Complex Network-Based Approach: Climate and Environment, pp 179-193, In: Water Resources and Environmental Engineering II. Springer Verlag, https://doi.org/10.1007/978-981-13-2038-5_17.
AGARWAL, A., Marwan, N., Rathinasamy, M., OZTURK, U., Merz, B., Kurths, J. (2018): Optimal Design of Hydrometric Station Networks Based on Complex Network Analysis, Hydrol. Earth Syst. Sci., doi.org/10.5194/hess-2018-113, in press.
Bronstert, A., AGARWAL, A., BOESSENKOOL, B., Crisologo, I., FISCHER, M., Heistermann, M., Köhn-Reich, L., López-Tarazón, J.A., MORAN, T., OZTURK, U., Reinhardt-Imjela, C. (2018): Forensic hydro-meteorological analysis of an extreme flash flood: The 2016-05-29 event in Braunsbach, SW Germany,Science of the Total Environment, 630: 977-991. doi.org/10.1016/j.scitotenv.2018.02.241.
Bronstert, A., Crisologo, I., Heistermann, M., OZTURK, U., VOGEL, K., WENDI, D. (2019): Flash-Floods: More often, More severe, More damaging? An Analysis of Hydro-Geo-Environmental Conditions and Anthropogenic Impacts, accepted for publication in: Springer Book Series "Climate Change Management”, Symposium on "Climate Change and Natural Hazards", University of Padova, Italy, 25-26/02/2019.
OZTURK U., Malik N., Cheung K., Marwan, N., Kurths J. (2019): A network-based comparative study of extreme tropical and frontal storm rainfall over Japan, Climate Dynamics, https://doi.org/10.1007/s00382-018-4597-1.
OZTURK U., Marwan N., Korup O., Saito H., AGARWAL A., Grossman M. J., Zaiki M., Kurths J. (2018a): Complex networks for tracking extreme rainfall during typhoons, Chaos, 28(7): 075301, https://doi.org/10.1063/1.5004480.
OZTURK, U., Marwan, N.,von SPECHT, S.,Korup, O., & Jensen, J. (2018b): A new centennial sea-level record for Antalya, eastern Mediterranean, Journal of Geophysical Research: Oceans, 123: 4503–4517, https://doi.org/10.1029/2018JC013906.
OZTURK U., WENDI D., Crisologo I., Riemer A., AGARWAL A., VOGEL K., López-Tarazón A. J., Korup O. (2018c): Rare flash floods and debris flows in southern Germany, Science of the Total Environment, 626: 941-952, https://doi.org/10.1016/j.scitotenv.2018.01.172.
VOGEL, K., OZTURK, U., Riemer, A., LAUDAN, J., SIEG, T., WENDI, D., AGARWAL, A., Rözer, V., Korup, O., Thieken, A.H. (2017a): Die Sturzflut von Braunsbach am 29. Mai 2016 - Entstehung, Ablauf und Schäden eines “Jahrhundertereignisses”. Teil 2: Geomorphologische Prozesse und Schadensanalyse, Hydrologie & Wasserbewirtschaftung, 61(3): 163-175, https://doi.org/10.5675/HyWa_2017,3_2.
von SPECHT, S., OZTURK, U., VEH, G., Cotton, F., Korup, O. (2019): Effects of finite source rupture on landslide triggering: The 2016 /M_W / 7.1 Kumamoto earthquake, Solid Earth, 10, 463-486, doi.org/10.5194/se-10-463-2019.
Thesis to download: